0. 들어가며...
현재 진행하고 있는 구름 PROTECT에서 구현한 API에 대한 성능테스트를 하고 있다. 필자는 진정한 대량의 성능 테스트를 위해서는 매번 다른 JWT 토큰 값이 Header에 담겨야 한다고 생각했다. 이유는 다음과 같다.
- 실제와 같은 환경을 최대한 구현할 수 있다. 실제 서비스에서도, 다른 사용자는 한 명도 사용하지 않는데, 한 사람만 요청을 5만 번 하는 경우는 극히 드물 것이다.
- 한 사람이 매번 같은 요청을 할 경우, DB 캐싱과 서버 캐싱으로 해당 내용이 메모리에 저장될 것이므로, 진정한 서버의 성능을 볼 수 없을 것이라 판단했다.
따라서 여러 명이 서비스를 각자 사용하고 있는 것을 흉내내고자 HEADER의 Authorization에 매 번 다른 토큰 값을 넣었다.
1. 토큰 생성 준비 하기
우리 팀의 회원가입 및 로그인은 KAKAO OAUTH2로 되어 있기에, 대량의 토큰을 카카오 로그인 루트로 가져오는 것은 힘들었다. 따라서 개발자용 토큰 생성기 API를 하나 만들었다.
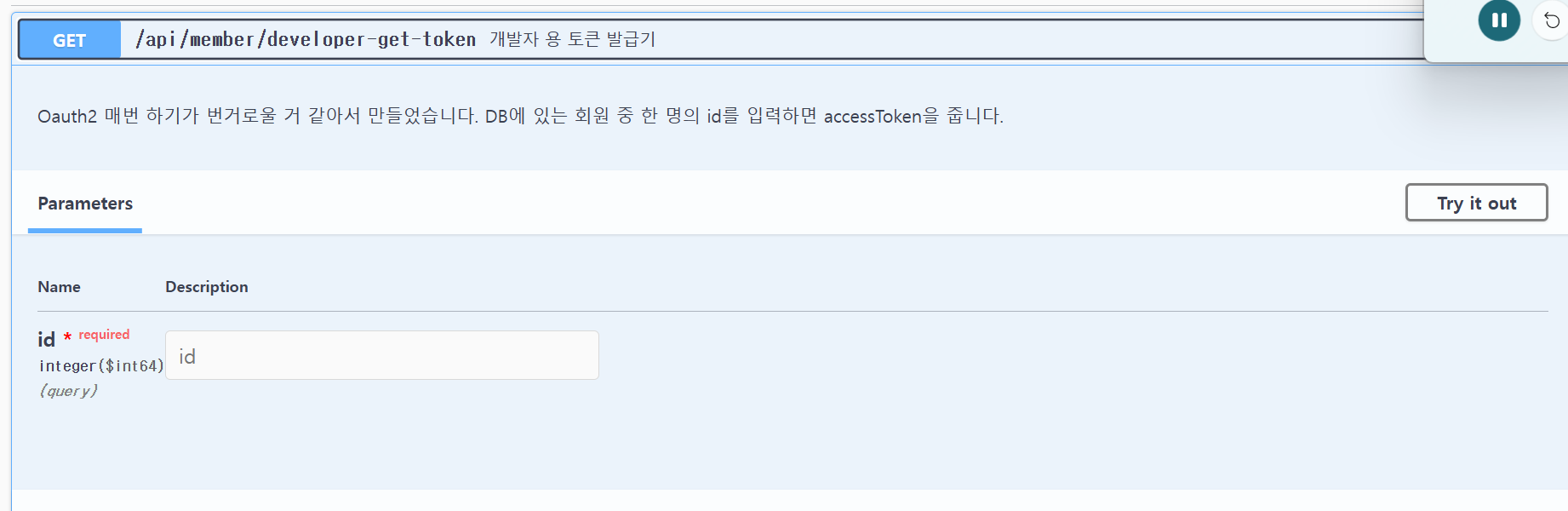
이제 여기에 member_id를 넣고, 토큰을 받으면 다음과 같이 나오는데, 이 JSON 중에서 accessToken을 파싱하여 꺼내서, 한 줄에 jwt 토큰 하나가 적힌 csv 파일을 만들어 보려고 한다.

2. 토큰 추출 및 수집기 (python)
import argparse
import csv
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
def fetch_token(i):
try:
url = f'http://{api 주소}/api/member/developer-get-token?id={i}'
response = requests.get(url, timeout=3)
if response.status_code == 200:
result = response.json()
if result.get('status') == 'success':
print(f"[{i}] 저장 성공")
return result['data']['accessToken']
else:
print(f"[{i}] 실패: {result.get('message')}")
else:
print(f"[{i}] HTTP 오류: {response.status_code}")
except Exception as e:
print(f"[{i}] 예외 발생: {e}")
return None
def collect_tokens(start_id, end_id, output_file, max_workers=10):
with open(output_file, mode='w', newline='') as file:
writer = csv.writer(file)
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = {executor.submit(fetch_token, i): i for i in range(start_id, end_id + 1)}
for future in as_completed(futures):
token = future.result()
if token:
writer.writerow([token])
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='accessToken 수집기')
parser.add_argument('--start', type=int, required=True, help='시작 ID')
parser.add_argument('--end', type=int, required=True, help='끝 ID')
parser.add_argument('--output', type=str, default='tokens.csv', help='저장할 CSV 파일명')
parser.add_argument('--workers', type=int, default=50, help='최대 동시 요청 수')
args = parser.parse_args()
collect_tokens(args.start, args.end, args.output, args.workers)
아까 받았던 json 응답 중 accessToken을 파싱 후 꺼내서 tokens.csv 라는 파일에 한 줄씩 적는다. 이걸 그냥 실행하면, 하나의 쓰레드가 모든 작업을 처리하기 때문에 느리다. 따라서 ThreadPoolExecutor를 활용해 병렬적 작업으로 처리하였다. PYTHON의 경우, GIL(Global Interpreter Lock)으로 인해, 동시에 여러 스레드가 Python 코드를 실행하지 못하지만 예외적으로 I/O 작업(API 요청, 파일 읽기, 네트워크)에는 GIL이 잠시 풀려서 병렬 쓰레드 작업이 가능하다.
# ThreadPool 이용한 멀티 스레드 작업
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = {executor.submit(fetch_token, i): i for i in range(start_id, end_id + 1)}
for future in as_completed(futures):
token = future.result()
if token:
writer.writerow([token])이를 실행하면 다음과 같이 파일 밑에 token 파일이 생긴다.