


1. 프로세스 주소 공간에 대해서 설명해주세요 .
프로세스 주소 공간에 대해서 설명 드릴려면, 먼저 프로세스가 메모리를 나누어 쓰는 방법인 메모리 가상화에 대해서 설명해야할 것 같습니다. 메모리 가상화란, 계속 해서 동일 자원을 돌려 쓰던 CPU 가상화와 달리, 물리적인 메모리를 쪼개고, 각 부분을 현재 실행 중인 프로세스에 대응시키는 방식을 말합니다. 이를 통해, 각 프로세스들은 마치 하나의 메모리를 자신이 혼자 쓰고 있는 것 같은 착각을 하게 되고 이 쪼개진 하나하나의 메모리를 가상화된 메모리라고 합니다.
이때 프로세스 하나 하나에 대응되는 가상화된 메모리를 프로세스의 주소공간이라고도 표현합니다.
프로세스의 주소 공간은 크게 코드 영역, 데이터 영역, 스택 영역, 힙 영역으로 나뉩니다.
| 1. 코드 영역 |
| 프로세스를 작동시킬 코드가 저장되는 영역, 사람이 진짜 짜는 코드가 아니라, 컴퓨터가 알아듣는 기계어가 저장된 영역 입니다. |
| 2. 데이터 영역 |
| 전역 변수, 정적 변수, 상수 등이 위치하는 영역 입니다. |
| 3. 스택 영역 |
| 함수의 호출과 관련된 정보를 저장하는 영역 입니다. 특정 함수가 호출될 때마다, 스택 영역에 해당 실행 Context가 쌓이게 되고, 스택 맨 위에 쌓인 순서대로 실행되고 스택에서 제거 됩니다. |
| 4. 힙 영역 |
| 런타임에 크기가 결정되는 영역이고 동적 메모리 할당을 위해 사용됩니다. 힙 영역은 개발자가 UserMode에서 직접 제어할 수 있는 영역으로 malloc()를 통해 할당하고, 해제는 free()함수를 이용해 할 수 있습니다. |
ⓐ 초기화 하지 않은 변수들은 어디에 저장될까요?
data 영역은 저장하는 값의 특성에 따라 data 영역(이름이 부모와 같습니다...) BSS 영역이 존재합니다. 여기서 초기화 되지 않은 변수들은 BSS 영역에 저장됩니다. 초기화 여부에 따라 구분하여 저장하는 이유는 초기화 되지 않은 변수들은 프로그램이 실행될 때만 영역을 잡아주면 되고, 평소에는 그 값을 프로그램에 저장할 필요가 없으나, 초기화가 이미 된 변수는 그 값을 프로그램에 저장하고 있어야 하기 때문입니다. 이게 BSS 영역이 존재하는 이유 입니다. BSS 영역 덕에 초기화 되지 않은 변수가 많아져도 프로그램의 실행코드 사이즈는 커지지 않습니다.
ⓑ일반적인 주소공간 그림처럼, Stack과 Heap의 크기는 매우 크다고 할 수 있을까요? 그렇지 않다면, 그 크기는 언제 결정될까요?
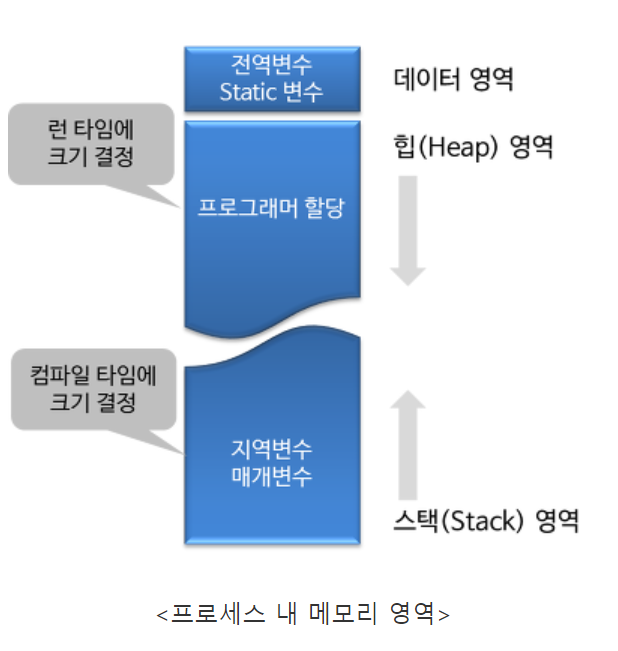
그림을 보시면, 스택과 힙 영역은 정확하게 영역이 정해져 있지 않은 것을 알 수 있습니다. 이유는 둘 사이 경계가 처음부터 힙이나 스택 어느 하나에 할당되어있는 것이 아니라, 둘 중 한 영역이 메모리 공간이 더 필요할 때 할당이 되기 때문입니다. 그래도 한 영역이 가질 수 있는 최대 영역은 정해져 있기 나름입니다. 예를 들어 비주얼 스튜디오의 경우에는 Stack 영역의 최대 크기는 1MB로 정해져 있고, 그 보다 많이 썼을 경우에 프로그램이 강제 종료 됩니다.
https://bozeury.tistory.com/90
힙(Heap)과 스택(Stack)의 최대 할당 크기
프로그래밍을 하면서 스택 영역, 힙 영역이라는 말을 많이 들어봤을 것이다.스택이나 힙은 한 프로세스 내에 존재하는 메모리 영역인데, 이 스택과 힙 메모리 공간을 얼마나 할당할 수 있는지
bozeury.tistory.com
ⓒ Stack과 Heap 공간에 대해 접근 속도가 더 빠른 공간은 어디일까요?
스택이 할당 속도가 HEAP에 비해 훨씬 빠르기 때문에 당연히 Stack에 접근하는 속도가 훨씬 빠릅니다. 스택은 이미 할당 되어있는 공간을 사용하는 것이고 힙은 사용자가 따로 할당해서 사용하는 공간 입니다. 다만 스택은 공간이 매우 적기 때문에 모든 응용에서 스택을 사용할 수는 없습니다.
ⓓ 프로세스의 주소 공간을 나누는 이유가 있을까요?
위와 같이 4가지로 구역을 나눈 이유는 데이터를 공유하여 메모리 사용량을 줄이기 위해서 입니다. CODE의 경우 프로그램 자체에서도 모두 같은 내용이기 때문에 관리하여 공유하고, Stack과 Data를 나눈 이유는 스택 구조의 특성과 전역 변수의 활용성을 위해서 입니다.
ⓔ 스레드의 주소공간은 어떻게 구성되어 있을까요?
스레드 주소 공간이란, 스레드가 생성되고 실행되는 동안 접근 가능한 메모리 영역으로 프로세스 주소 공간 내에 형성합니다. 스레드 주소 공간은 스레드 사적 공간과 스레드 사이의 공유 공간으로 나누어지며, 사적 공간은 스레드 코드, 스레드 로컬 스토리지, 스레드 사용자 스택, 스레드 커널 스택 등으로 구성되고, 공유 공간에는 프로세스 처럼 스레드 코드, 데이터,힙, 스택 영역으로 나누어져 있습니다.
ⓓ IPC의 Shared Memory 기법은 프로세스 주소 공간의 어디에 들어가나요? 그런 이유가 있을까요?
shared Memory 기법은 커널 영역의 메모리에 변수를 할당하여, 공유 변수처럼 사용하는 방식입니다. 프로세스가 공유 메모리 할당을 커널에 요청하면 커널은 해당 프로세스에 메모리 공간을 할당해줍니다. 공유 메모리 영역이 프로세스 주소공간 내에 구축된 이후에는 모든 접근이 일반적인 메모리 접근으로 취급되기 때문에 더 이상 커널의 도움 없이도 각 프로세스의 해당 메모리 영역에 접근할 수 있습니다.
2. 단기 중기 장기 스케줄러에 대하여
장기 스케줄러 , 어떤 프로세스를 준비큐에 넣을 것인가? 를 담당합니다.
작업 스케줄러라고도 부르며, 어떤 프로세스를 준비 큐에 삽입할지를 결정하는 역할을 합니다.
단기 스케줄러(short term scheduler) : 어떤 프로세스에게 cpu를 할당해 줄 것인가 ?
중기 스케줄러(medium term scheduler) : 메모리에 적재된 프로세스 수 관리
ⓐ 프로세스 상태 전이
✓ 승인 (Admitted) : 프로세스 생성이 가능하여 승인됨.
✓ 스케줄러 디스패치 (Scheduler Dispatch) : 준비 상태에 있는 프로세스 중 하나를 선택하여 실행시키는 것.
✓ 인터럽트 (Interrupt) : 예외, 입출력, 이벤트 등이 발생하여 현재 실행 중인 프로세스를 준비 상태로 바꾸고, 해당 작업을 먼저 처리하는 것.
✓ 입출력 또는 이벤트 대기 (I/O or Event wait) : 실행 중인 프로세스가 입출력이나 이벤트를 처리해야 하는 경우, 입출력/이벤트가 모두 끝날 때까지 대기 상태로 만드는 것.
✓ 입출력 또는 이벤트 완료 (I/O or Event Completion) : 입출력/이벤트가 끝난 프로세스를 준비 상태로 전환하여 스케줄러에 의해 선택될 수 있도록 만드는 것.
ⓑ 비선점 스케줄링에 대하여
비선점 스케줄링이란 Context Switching 없이 온 순서 그대로 일이 진행되는 스케줄링을 말한다. 비선점 스케줄링에는
- FCFS (First Come First Served)
- 큐에 도착한 순서대로 CPU 할당
- 실행 시간이 짧은 게 뒤로 가면 평균 대기 시간이 길어짐
- SJF (Shortest Job First)
- 수행시간이 가장 짧다고 판단되는 작업을 먼저 수행
- FCFS 보다 평균 대기 시간 감소, 짧은 작업에 유리
- HRN (Hightest Response-ratio Next)
- 우선순위를 계산하여 점유 불평등을 보완한 방법(SJF의 단점 보완)
- 우선순위 = (대기시간 + 실행시간) / (실행시간)
ⓒ 선점 스케줄링에 대하여
- Priority Scheduling
- 정적/동적으로 우선순위를 부여하여 우선순위가 높은 순서대로 처리
- 우선 순위가 낮은 프로세스가 무한정 기다리는 Starvation 이 생길 수 있음
- Aging 방법으로 Starvation 문제 해결 가능
- Round Robin
- FCFS에 의해 프로세스들이 보내지면 각 프로세스는 동일한 시간의 Time Quantum 만큼 CPU를 할달 받음
- Time Quantum or Time Slice : 실행의 최소 단위 시간
- 할당 시간(Time Quantum)이 크면 FCFS와 같게 되고, 작으면 문맥 교환 (Context Switching) 잦아져서 오버헤드 증가
- FCFS에 의해 프로세스들이 보내지면 각 프로세스는 동일한 시간의 Time Quantum 만큼 CPU를 할달 받음
- Multilevel-Queue (다단계 큐)
- 작업들을 여러 종류의 그룹으로 나누어 여러 개의 큐를 이용하는 기법

- 우선순위가 낮은 큐들이 실행 못하는 걸 방지하고자 각 큐마다 다른 Time Quantum을 설정 해주는 방식 사용
- 우선순위가 높은 큐는 작은 Time Quantum 할당. 우선순위가 낮은 큐는 큰 Time Quantum 할당.
- 4.Multilevel-Feedback-Queue (다단계 피드백 큐)
- 다단계 큐에서 자신의 Time Quantum을 다 채운 프로세스는 밑으로 내려가고 자신의 Time Quantum을 다 채우지 못한 프로세스는 원래 큐 그대로
- Time Quantum을 다 채운 프로세스는 CPU burst 프로세스로 판단하기 때문
- 짧은 작업에 유리, 입출력 위주(Interrupt가 잦은) 작업에 우선권을 줌
- 처리 시간이 짧은 프로세스를 먼저 처리하기 때문에 Turnaround 평균 시간을 줄여줌
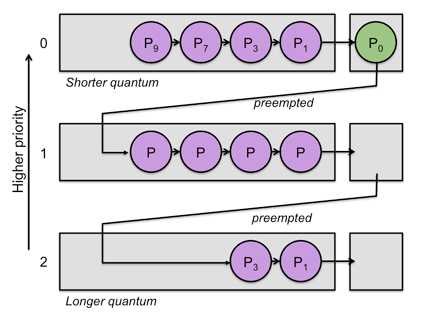
- 다단계 큐에서 자신의 Time Quantum을 다 채운 프로세스는 밑으로 내려가고 자신의 Time Quantum을 다 채우지 못한 프로세스는 원래 큐 그대로
- 작업들을 여러 종류의 그룹으로 나누어 여러 개의 큐를 이용하는 기법
ⓓ Process Context Switching vs Thread Context Switching
프로세스는 하나 이상의 쓰레드를 포함한다. 이 쓰레드들은 고유한 Stack영역의 메모리와 고유한 registers를 할당 받으며 Heap영역의 메모리에서 선언된 데이터는 서로 공유한다.
동일한 프로세스 속에서 thread context switching이 발생할 경우 processor는 stack영역의 주소와 registers 주소를 포함한 thread의 context 정보만을 변경하면 된다.
하지만 process context switching이 발생할 경우 processor는 thread의 context뿐만 아니라 process의 context까지 모두 변경해야 한다.
선점, 비선점 모두에 존재할 수 없는 상태가 있나요?
-네, 존재합니다. 예를 들어 블록 상태가 있습니다. 블록 상태는 작업 실행이 불가능한 상태로, 작업이 사전 정의된 다른 작업이 완료될 때까지 수행이 중지되는 상태입니다. 따라서 블록 상태는 preemptive 및 non-preemptive 스케줄링 모두에 존재할 수 없습니다.
