


0. 학습목적
- 인덱스에 대한 개괄적인 이해 ( 아 이런 거구나~ 정도만 얻으면 OK)
1. 인덱스란?
원하는 데이터를 바로 찾아보기 위한 색인을 말한다.
책의 목차나 책 말미에 존재하는 원하는 글 찾아보기와 같은 기능을 한다.
2. 인덱스의 구조
계속 책의 관점과 비교해서 설명하겠다.
위의 그림은 국어 사전의 맨 끝에 있는 원하는 단어의 뜻 찾아보기이다. (이하 색인이라 부르겠다.)
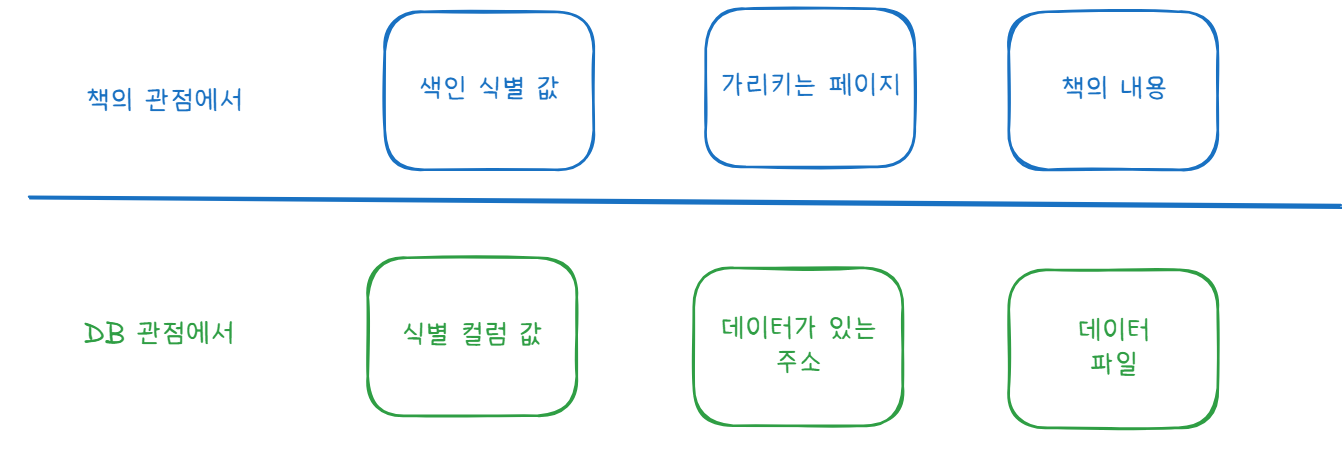
해당 색인에서는 a. 원하는 단어 이름을 찾은 뒤, b. 그것이 가리키는 페이지로 가서 c. 책의 내용을 본다.
DB의 INDEX 또한 해당 원리를 그대로 이어 나간다. 국어사전에서 원하는 단어 이름과 같이 개별 인덱스들을 식별할 수 있는 a. 식별 컬럼 값이 존재 하며, 그것마다 Pair 값으로 b. 데이터가 존재하는 주소를 가지고 있다. 이제 해당 주소로 가면 내가 원하던 c. 데이터 파일 을 읽을 수 있게 되는 것이다.
구조를 도식화하면 다음과 같다.
인덱스만 따로 떼어내서 보면 다음과 같을 것이다.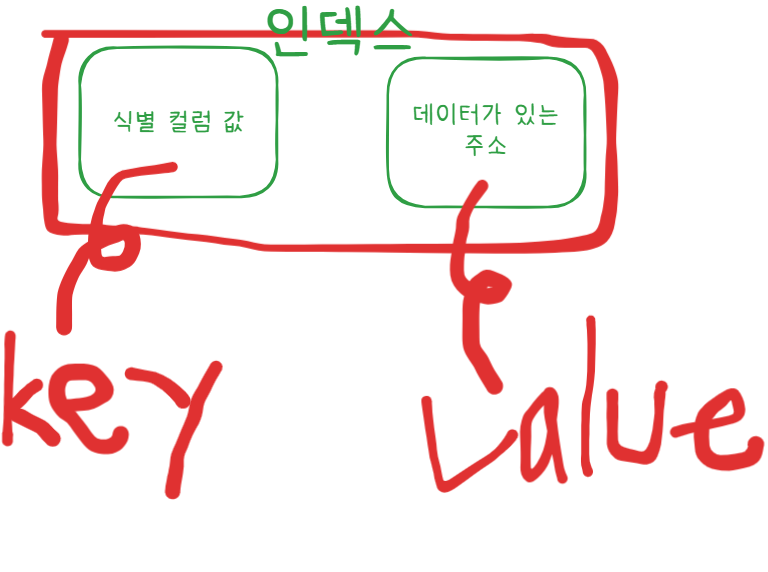
마치 HashMap의 Key-value Pair처럼 되어 있다.
3. 인덱스의 특성
결론: 인덱스의 값들은 식별 컬럼 기준으로 정렬되었다.
국어사전의 색인을 보면, 글자를 오름 차순 정렬 해놓았음을 알 수 있다. ㄱ,ㄴ,ㄷ,ㄹ 자음 순으로 시작하여 세부 정렬은 다시 모음 순으로 진행하고 있다.
이와 똑같이 인덱스 또한 특정 기준으로 인덱스 컬럼들이 정렬됨이 보장된다. 이렇게 정렬된 기준이 존재해야 스토리지 엔진 또한 원하는 값을 찾을 수 있기 때문이다.
A. 해당 특성으로 찾아오는 여파
결론: 인덱스 사용은 등가 교환 (특정 테이블에 인덱스를 생성할수록 삽입, 수정, 삭제 속도 저하, 조회 속도 UP)
인덱스와 원본 데이터 파일을 자료 구조에 비교하자면, 인덱스는 SortedSet이며, 원본 데이터 파일은 ArrayList이다.
즉 인덱스는 저장, 수정, 삭제 시 정렬의 정합성을 깨지 않기 위해, 제자리를 찾아가며 저장되지만, ArrayList는 그저 삽입된 순으로 저장되며, 수정 삭제 시 모든 데이터를 순차적으로 확인해서 자신이 지울 것의 위치를 찾는다.
따라서 인덱스를 생성한다는 것은 조회와 그 외의 DML의 속도를 등가 교환 하는 행위이기 때문에, 현 서비스에서 특정 조회 속도를 늘리기 위해 삽입, 삭제, 조회를 어느 정도 희생할 수 있을지 개발자가 적절히 판단해야 한ㄷ.
4. 인덱스의 종류
인덱스를 구분하는 기준에 따라 종류를 다르게 셀 수 있다.
(1) 색인의 기준인 컬럼 값을 무엇으로 지정하는가
PK인덱스:
본 테이블의 대표 식별 컬럼(Primary Key) 자체를 인덱스 식별 컬럼으로 활용하는 방법을 말한다.
보조 (Secondary)인덱스:
본 테이블의 PK를 제외한 컬럼을 인덱스 식별 컬럼으로 활용하는 방법을 말한다.
(2) 데이터 저장 방식
B-tree인덱스:
식별 컬럼의 값을 변형하지 않고, 원본 데이터 속 칼럼 값을 그대로 사용하여 인덱싱하는 방식Hash인덱스:
원본 데이터 속 컬럼 값을 해싱 알고리즘으로 해싱해서 식별 컬럼으로 사용하는 방식
(3) 데이터 중복 허용 여부
Unique인덱스:
식별 컬럼 값이 모든 레코드마다 다름 (즉 모든 값이 유일무이함)Non-unique인덱스:
위와 반대 즉, 식별 컬럼의 값이 중복될 수 있음
5. 핵심 요약
인덱스의 구조는 국어사전의 원하는 단어 찾아보기와 같다.
식별 컬럼으로 찾고 싶은 데이터 특정 -> 식별 컬럼의 Pair 값인 데이터 주소로 원본 데이터 파일을 찾는다.
인덱스는 정렬된 채 저장이라서 신규 값 입력 시 매번 제 위치 찾는 작업을 해야한다.
따라서 인덱스 생성은 조회 속도를 높이지만, 삽입, 수정, 삭제 속도를 낮춘다.
Metadata
A. 참고 문서
- 없음
B. 모르는 단어 정리 to Layman's term 𓂃🖊
- 없음
C. 자식 글
TABLE without id file.inlinks AS "BackLink"
WHERE file.path = this.file.path


